Hadoop学习笔记(1)
——菜鸟入门
Hadoop是什么?先问一下百度吧:
【百度百科】一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop主要用于一些分布式计算。在这个大数据年代,那这个的确是一个很不错的工具。所以很有必要来学一学。
如何开展这个学习呢,不管怎样,学习一样新东西,我喜欢这样的顺序:先依葫芦画瓢,一步一步行将其运行起来,再来分析一些应用场景及运行的情况,然后深入看一下其高级应用, 最后由于这个是一个开源产品,正好来借此机会来读一读大牛们的代码,学学其精华。
好了,开始行动:
- 运行环境搭建
首先,这个是需要运行在linux系统中的,所以得安装个linux才行,市面上有很多个linux的版本,如红帽子、Fedra、Ubuntu。选哪种呢,对我这种习惯windows的来说,当然要使用方便的,所以选择了Ubuntu。
安装Ubuntu,这里我就不多说了,在官网上有很多,其实也很简单,一路下一步。当然这里可以安装在Vmware虚拟机上,也可以直接安装在硬盘上。 我个人建议,可以直接安装在硬盘上,与现有windows做个双系统。因为后面还要跑开发环境 eclipse,在虚拟机上会有点吃力。 同时安装在硬盘上后,还可以这样玩,在进入windows后,安装 vmware,然后新建虚拟机后,不要创建硬盘,直接使用硬盘的分区,这样, 就可以在vmware中启动安装在硬盘上的ubuntu了。做到双系统,双启动。
这样好处是,当要开发时,可以直接进ubuntu系统,当只是看看代码,以及后面模拟分布式部署时,就可以用vmware来启动,同时再建上几个虚拟机来进行分布式部署。
操作系统准备好后,就需要一些组件了,hadoop比较简单,只需要ssh和java环境,再加个下代码的SVN。
先用 sudo apt-get install subversion ssh ant 这个命令,把SSH、Ant和SVN安装起来。
java环境,可以在网上下载一个JDK安装包,如:jdk-6u24-linux-i586.bin
安装直接在目录下运行./jdk-6u24-linux-i586.bin即可。
然后配置jdk目录:
先进入安装目录 cd jdk-6u24-…
然后输入 PWD 就可以看到java安装目录,复制下来:

命令行执行:sudo gedit /etc/profile
在打开的文件里,追加:
export JAVA_HOME=/home/administrator/hadoop/jdk1.6.0_27 //这里要写安装目录
export PATH=${JAVA_HOME}/bin:$PATH
执行source /etc/profile 立即生效
验证是否安装完成,那比较容易了,在命令行下运行 java -version ant svn ssh 看是否找不到命令,如果都能找到,说明OK了。
- 下载代码:
这是个开源的系统,代码很方便用SVN就可以下载到,版本也很多,在这里我选择0.20.2版本,一个是网上好多书都基于这个版本的,另外是看源码,还是以前点版本吧,后面的版本里面肯定又加了很多。
运行这个命令来下载:
svn co http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.20.2/
下载完成后,会在当前文件夹内产生一个新文件夹release-0.20.2,这里面就是代码了。
为了后面方便操作,把这文件夹重命令一下:
mv release-0.20.2/ hadoop-0.20.2
好了,用图形界面进入该文件夹,看一看:
- 编译代码
刚下完的代码是无法直接运行的,需要编译一下,但用什么编译呢?
编译前先修改一下build.xml,打开,将里面的版本号改成:0.20.2,如下:

看到代码里面有个build.xml,这个是典型的用ant编译用的配置文件,所以直接在命令行里输入:
~/hadoop-0.20.2$ant
~/hadoop-0.20.2$ant jar
~/hadoop-0.20.2$ant examples
[注意] 编译时需要联网,否则在自动下载jar包时会挂掉。
然后屏幕会刷啊刷,等到完成看到下面字符时,也就OK了:
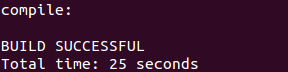
- 配置SSH
我们了解到,这个hadoop是支持分布式运行的,每台机器到时都会来安装hadoop程序,如果想启动所有程序怎么办? 一台台去启动? 那也太土了, 当然是远程去启动咯。为实现这个目标,就得用上SSH了。
SSH是什么,说白了,这个就是一个远程登陆器,跟远程桌面、telnet差不多。在linux上所有操作都可以用命令行来完成,所有SSH也就是一个命令行形式,同时比telnet高级,因为通过了加密通道传输信息。
那我们就部署了一台机器,还要这个SSH吗? 答案是要的,因为在运行hadoop里,即使是本机的,里面也要通过SSH localhost的方式来启动,这样代码统一。
前面不是安装过SSH了么,还要配置什么?SSH正常登陆时,是需要输入用户名密码的,但是当所有的hadoop子服务都受主服务管了后,最好就直接信任了,不要输入帐号信息,所以我们配置的目的也就是这个。
先试一下,我用SSH登陆当前本机信息:

可以看到,登陆本机时,也要输入一下密码,怎么办?
SSH是能过RSA加密的,所以有公钥私钥的说法,所以,我们先产生一对固定的公私钥,运行这个ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa命令:

这里产生公私钥,并生成在.ssh文件夹下,于是我们就进入看一下:
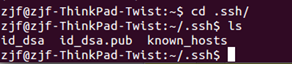
果然,这里多了两个文件,id_dsa为私钥,id_dsa.pub为公钥
然后再把公钥复制成authorized_key,即将这个公钥固定为SSH登陆所用。

这步很重要,做完这步后,就可以再试一下登陆本机了:
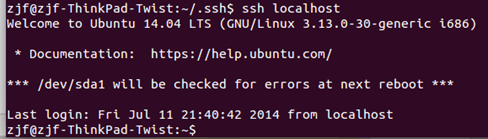
看,现在再ssh localhost时,就直接进入,没有再输入帐号了。
到这里,SSH配置就成功了。
- 修改配置文件
在正式运行之前,还要修改一下配置文件才地,这里具体的配置参数,就不讲,葫芦画瓢么,先跑起来,后面再来研究这是为啥:
在代码的conf文件夹内,就可以找到下面几个配置文件,分别配置成以下内容:
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zjf/hadoop-0.20.2/tmpPath</value> !这里改下路径
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
修改conf/hadoop-env.sh
将里面的JAVA_HOME注释打开,并把里面的地址配置正确。
- 运行
Hadoop是一头神奇的大象,那我们得站在大象背上说句Hello world了。
进入hadoop目录: $cd Hadoop-0.20.2
首次运行,需要对namenode进行格式化:bin/hadoop namenode -format
启动hadoop:
bin/start-all.sh
关闭hadoop可以用:
bin/stop-all.sh
如果验证启动成功呢?有两种方式
- 访问一下管理页面看:
Job跟踪:
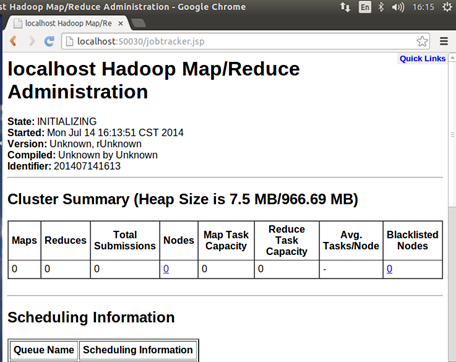
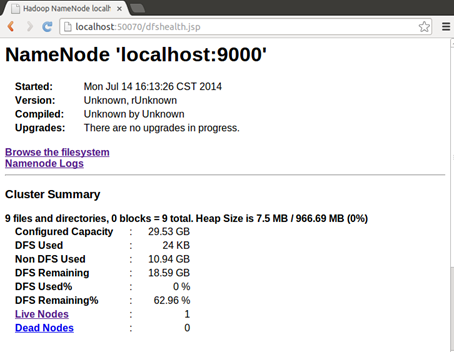
NameNode结点:
- 用jps看一下有几个java进程在运行,如果是下面几个就正常了:

主要有DataNode NameNode SecondaryNameNode TaskTracker JobTracker这几个进程,就表示正常了
系统启动正常后,跑个程序吧
$mkdir input
$cd input
$echo "hello world">test1.txt
$echo "hello hadoop">test2.txt
$cd ..
$bin/hadoop dfs -put input in
$bin/hadoop jar build/hadoop-0.20.2-examples.jar wordcount in out
$bin/hadoop dfs -cat out/*

最关健的是,最后输入:

输出这个结果这就表示我们的程序运行成功了。至于这结果是什么意思,我想看到后大概也猜到了吧,至于详细解说,下期再看。
http://www.cnblogs.com/zjfstudio/p/3859704.html